 Wie lässt sich der Auslöser der Videokamera durch eine Objekterkennung im Videobild selbst steuern? Das ist die Fragestellung um die es in diesem Artikel geht. In den beiden vorhergegangenen hatten wir bereits Vorarbeiten geleistet. Wir hatten OpenCV als Python Programmbibliothek installiert und das Video-Aufzeichnungsprogramm so erweitert, dass es jede Sekunde ein Bild aus dem aktuellen Videodatenstrom entnimmt und ins Dateisystem legt. Nun können wir diese Bilder einlesen und auf die Fellfarben der typischen deutschen Eichhörnchen hin analysieren. Bei positiver Erkennung soll eine Triggerdatei erzeugt werden – genauso, wie es vorher durch den Bewegungssensor geschehen ist.
Wie lässt sich der Auslöser der Videokamera durch eine Objekterkennung im Videobild selbst steuern? Das ist die Fragestellung um die es in diesem Artikel geht. In den beiden vorhergegangenen hatten wir bereits Vorarbeiten geleistet. Wir hatten OpenCV als Python Programmbibliothek installiert und das Video-Aufzeichnungsprogramm so erweitert, dass es jede Sekunde ein Bild aus dem aktuellen Videodatenstrom entnimmt und ins Dateisystem legt. Nun können wir diese Bilder einlesen und auf die Fellfarben der typischen deutschen Eichhörnchen hin analysieren. Bei positiver Erkennung soll eine Triggerdatei erzeugt werden – genauso, wie es vorher durch den Bewegungssensor geschehen ist.
Zuerst aber wieder ein Oachkatzl-Video. Mehr davon gibts in meinem YouTube-Kanal.

Zur Wahrung deiner Privatsphäre wird erst eine Verbindung zu YouTube hergestelt, wenn du den Abspielbutton betätigst.
So soll es funktionieren
Im vorangegangenen Artikel hatten wir das Video-Aufzeichnungsprogramm (heißt bei mir jetzt record2.py) so modifiziert, dass jede Sekunde ein aktuelles Kamerabild als /tmp/record.jpg gespeichert wird. An sich braucht ein Analyseprogramm jetzt nur noch drei Dinge tun:
- Die Bilddatei einlesen. Um dafür den richtigen Zeitpunkt zu erwischen, hilft die Signaldatei, die vom Aufzeichnungsprogramm immer dann nach
/tmp/geschrieben wird, wenn die Bilddatei gültig ist. - Das Bild nach Eichhörnchenfarben durchsuchen. Das machen wir mit OpenCV, einer sehr mächtigen Bibliothek, wenn es um Bildauswertung geht.
- Im Fall der Fälle eine Triggerdatei schreiben und später wieder entfernen. Zur Erinnerung: Eine Triggerdatei sagt dem Video-Aufzeichnungsprogramm, dass es aufnehmen soll.
Diese drei Aufgaben finden wir im Python-Programm in Form von drei Klassen wieder, die da heißen:
imageLoaderimageAnalyzertriggerGenerator
Das Analyseprogramm zur Farberkennung komplett (analyze.py)
import os
import time
import datetime
import cv2
import numpy as np
imagePath = "/tmp/" # path to image and timestamp files
tsExt = ".sig" # file extension of timestamp file
imageFile = "record.jpg" # name of image file
alpha = 0.1 # amount of influence of a single value to the computed average
sigma = 7.0 # value to multipy volatility with for a higher threshold
minPix = 275 # minimum pixel to detect
sunset = 60 # lower brightnes switches to night
sunrise = 65 # higher brightness switches to day
triggerTimeout = 20 # min. trigger duration, time extends, when triggered again
triggerFileExt = '.trg' # file extension for trigger signal file
triggerPath = 'trigger/' # path for trigger signal file
class imageLoader:
def __init__(self):
self.timeout = datetime.timedelta(0, 1) # default 1sec
self.lastTsTime = datetime.datetime.now() - self.timeout # time of last timestamp
self.lastTs = "" # last timestamp as a string
def readTimeStamp(self):
# Read names of all timestamp files, take the first (should be only one) and isolate timestamp
tsFiles = [f for f in os.listdir(imagePath) if f.endswith(tsExt)]
if len(tsFiles) > 0:
return tsFiles[0][0:-4]
else:
return False
def getImg(self):
# sleep until next expected image file, wait for valid time stamp file and then read image file
# adjust sleep time until next image (+/- 0.01sec)
wTime = (self.timeout - (datetime.datetime.now() - self.lastTsTime)).total_seconds()
if wTime > 0:
# print(wTime)
time.sleep(wTime)
ts=self.readTimeStamp()
if not ts or (ts == self.lastTs):
self.timeout += datetime.timedelta(milliseconds=10)
time.sleep(0.01)
ts=self.readTimeStamp()
while not ts or (ts == self.lastTs):
time.sleep(0.01)
ts=self.readTimeStamp()
else:
self.timeout -= datetime.timedelta(milliseconds=10)
self.lastTsTime = datetime.datetime.now()
self.lastTs = ts
return (ts, cv2.imread('/tmp/record.jpg',1))
class imageAnalyzer:
def __init__(self):
self.avgPix = -1 # average number of detected pixel
self.avgVola = -1 # average volatility (gap between number of detected pixel and their average value)
self.night = False # indicator for day or night
def detect(self, img, ts):
# Detect whether day or night
# Convert to grayscale
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# Brightness is the average of all pixels
brightness = np.average(gray)
# Change from night to day or vice versa
if self.night and brightness > sunrise: self.night = False
if not self.night and brightness < sunset: self.night = True
# Find matching pixel (for red and brown squrrel) in image
# Convert BGR to HSV
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# define range of red color in HSV
lower_value = np.array([0,70,110])
upper_value = np.array([11,170,220])
maskRed = cv2.inRange(hsv, lower_value, upper_value)
lower_value = np.array([165,70,110])
upper_value = np.array([179,170,220])
maskRed2 = cv2.inRange(hsv, lower_value, upper_value)
# define range of brown color in HSV
lower_value = np.array([12,40,220])
upper_value = np.array([17,65,255])
maskBrown = cv2.inRange(hsv, lower_value, upper_value)
lower_value = np.array([125,30,45])
upper_value = np.array([170,65,110])
maskBrown2 = cv2.inRange(hsv, lower_value, upper_value)
# Mask for red and brown
mask = maskRed+maskRed2+maskBrown+maskBrown2
pixDetected = cv2.countNonZero(mask)
# special case: average values not yet computed
if self.avgPix == -1:
self.avgPix = pixDetected
self.avgVola = minPix * sigma
# calc threshold (pixDetected must be higher for a valid object detection)
movingBand = self.avgVola * sigma
if movingBand < minPix:
movingBand = minPix
threshold = self.avgPix + movingBand
print("{0} Pix: {1:5d} Avg: {2:5.0f} Vola: {3:5.0f} Thresh: {4:5.0f} Bright: {5:3.0f} {6}{7}" \
.format(ts, pixDetected, self.avgPix, self.avgVola, threshold, brightness, \
"-" if self.night==True else " ", \
"T" if pixDetected >= threshold else ""))
# cv2.imwrite('result.jpg',mask)
# cv2.imwrite('result1.jpg',img)
# no object detection because it is night or amount of detected pixel is below threshold
if self.night or pixDetected < threshold:
# update average values
self.avgVola = abs(pixDetected-self.avgPix)*alpha + self.avgVola*(1-alpha)
self.avgPix = pixDetected*alpha + self.avgPix*(1-alpha)
return False
# valid object detection
# cv2.imwrite('Videos/'+ts+'-1.jpg',mask)
# cv2.imwrite('Videos/'+ts+'-2.jpg',img)
return True
class triggerGenerator:
def __init__(self):
self.triggered = False # Trigger currently active?
self.lastTrigger = datetime.datetime.now() # stores last time of trigger detction
def trigger(self, triggerSignal, ts):
if triggerSignal:
# set or prolongation of trigger signal (zero length file), when new trigger detected
if not self.triggered:
open(triggerPath+ts+triggerFileExt, 'w').close()
self.triggered = True
print('Triggerstart')
self.lastTrigger = datetime.datetime.now()
else:
# remove trigger signal (zero length file) if timed out
if not self.triggered:
return
now = datetime.datetime.now()
if (now - self.lastTrigger).total_seconds() > triggerTimeout:
triggerFiles = [f for f in os.listdir(triggerPath) if f.endswith(triggerFileExt)]
for f in triggerFiles:
os.remove(triggerPath+f)
self.triggered = False
print('Triggerstop')
il = imageLoader()
ia = imageAnalyzer()
tg = triggerGenerator()
while True:
timeStamp, img = il.getImg()
tSignal = ia.detect(img, timeStamp)
tg.trigger(tSignal, timeStamp)Aber beginnen wir am Anfang.
Imports
Os brauchen wir um Dateien lesen und schreiben zu können und time und datetime für Zeitstempel und um das Programm für eine Weile schlafen zu legen. Neu sind cv2 für OpenCV und numpy für das Handling von multidimensionalen Arrays.
Globale Variablen als Parameterkonstanten
Hier kennen wir einige bereits, wie zum Beispiel die Pfade und Dateierweiterungen für Signal- und Triggerdateien. Die anderen Einstellmöglichkeiten werden dann bei den entsprechenden Klassen erklärt.
Klasse imageLoader
Dieser Programmteil hat die Aufgabe jede Sekunde eine Bilddatei einzulesen und sie der weiteren Verarbeitung zur Verfügung zu stellen. Hier nochmal der entsprechende Programmausschnitt um ein ständiges Hochblättern beim Lesen zu vermeiden:
...
class imageLoader:
def __init__(self):
self.timeout = datetime.timedelta(0, 1) # default 1sec
self.lastTsTime = datetime.datetime.now() - self.timeout # time of last timestamp
self.lastTs = "" # last timestamp as a string
def readTimeStamp(self):
# Read names of all timestamp files, take the first (should be only one) and isolate timestamp
tsFiles = [f for f in os.listdir(imagePath) if f.endswith(tsExt)]
if len(tsFiles) > 0:
return tsFiles[0][0:-4]
else:
return False
def getImg(self):
# sleep until next expected image file, wait for valid time stamp file and then read image file
# adjust sleep time until next image (+/- 0.01sec)
wTime = (self.timeout - (datetime.datetime.now() - self.lastTsTime)).total_seconds()
if wTime > 0:
# print(wTime)
time.sleep(wTime)
ts=self.readTimeStamp()
if not ts or (ts == self.lastTs):
self.timeout += datetime.timedelta(milliseconds=10)
time.sleep(0.01)
ts=self.readTimeStamp()
while not ts or (ts == self.lastTs):
time.sleep(0.01)
ts=self.readTimeStamp()
else:
self.timeout -= datetime.timedelta(milliseconds=10)
self.lastTsTime = datetime.datetime.now()
self.lastTs = ts
return (ts, cv2.imread('/tmp/record.jpg',1))
...Die Klasse hat drei Methoden. Im Konstruktor __init__ werden drei Variablen definiert, die den Status zwischen den Aufrufen halten. Die Methode readTimeStamp ist nur ein Unterprogramm, das von der nächsten Methode gebraucht wird und kümmert sich darum, nachzusehen, ob eine Signaldatei (timestamp file) vorhanden ist. Im positiven Fall wird der Timestamp zurückgeliefert, das ist der Dateiname der Signaldatei ohne das .sig am Ende. Liegt keine Signaldatei im Verzeichnis, wird False zurückgegeben.
![]() getImg
getImgwTime berechnet. Das ist eine kalkulierte und ständig angepasste Wartezeit bis zu dem Zeitpunkt, an dem die nächste Signaldatei erwartet wird. Interessant kann es sein hier mal testweise die Raute vor print(wTime) wegzunehmen. Dieser Zeitwert stellt quasi die Freizeit des Programms dar, für die es sich Schlafen legt, nachdem das Bild fertig analysiert ist. Hier kann man also sehen, wie gut die gesamte Bildauswertung mit der vorgegebenen Zeit von einer Sekunde zwischen zwei Bildern zurecht kommt. Da OpenCV rasend schnell ist, wird ein Wert knapp unter einer Sekunde herauskommen, oder auch mal etwas mehr, weil das Video-Aufzeichnungsprogramm etwas länger als eine Sekunde braucht.
time.sleep(wTime) schickt das Programm jetzt erst mal für die kalkulierte Dauer Schlafen. Danach wird versucht eine Signaldatei per self.readTimeStamp() zu lesen. Kann keine Signaldatei gelesen werden oder hat die gelesene noch den Zeitstempel der vorhergegangenen, dann sind wir zu früh aufgewacht und es muss noch etwas gewartet werden. Dazu wird jetzt einmalig der gespeicherte Timeoutwert self.timeout um 10ms vergrößert und dann in 10ms-Abständen neu probiert eine Signaldatei zu lesen. Im anderen Fall, wenn beim ersten Versuch bereits eine neue Signaldatei gelesen werden kann, dann sind wir mit dem Aufwachen tendenziell zu spät dran und der Timeoutwert wird vorsorglich um 10ms verkürzt. So passt sich der Timeout ständig an, um dem Erscheinen der neuen Signaldatei möglichst nahe zu sein, ohne dass ununterbrochen danach gepollt werden muss. Und warum macht das Programm das? Aus einem einfachen Grund: In dem Moment, in dem eine neue Signaldatei vom Video-Aufzeichnungsprogramm geschrieben wird, ist eine neue Bilddatei fertig geschrieben und genau jetzt haben wir die maximale Zeit (von fast einer Sekunde) zur Verfügung um sie einzulesen. Und genau das macht die Methode zum Abschluss, sie gibt den Zeitstempel der aktuellen Signaldatei und das Bild an das aufrufende Programm zurück. Das Einlesen des Bilds aus dem Dateisystem (in der return-Zeile) erfolgt bereits mit OpenCV (cv2.imread). Dadurch haben wir das Bild in einem CV-kompatiblen Zahlenformat zur Verfügung.
Klasse imageAnalyzer
Der ImageAnalyzer beinhaltet die eigentliche Farbauswertung. Auch hier nochmal der Programmcode:
...
class imageAnalyzer:
def __init__(self):
self.avgPix = -1 # average number of detected pixel
self.avgVola = -1 # average volatility (gap between number of detected pixel and their average value)
self.night = False # indicator for day or night
def detect(self, img, ts):
# Detect whether day or night
# Convert to grayscale
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# Brightness is the average of all pixels
brightness = np.average(gray)
# Change from night to day or vice versa
if self.night and brightness > sunrise: self.night = False
if not self.night and brightness < sunset: self.night = True
# Find matching pixel (for red and brown squrrel) in image
# Convert BGR to HSV
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# define range of red color in HSV
lower_value = np.array([0,70,110])
upper_value = np.array([11,170,220])
maskRed = cv2.inRange(hsv, lower_value, upper_value)
lower_value = np.array([165,70,110])
upper_value = np.array([179,170,220])
maskRed2 = cv2.inRange(hsv, lower_value, upper_value)
# define range of brown color in HSV
lower_value = np.array([12,40,220])
upper_value = np.array([17,65,255])
maskBrown = cv2.inRange(hsv, lower_value, upper_value)
lower_value = np.array([125,30,45])
upper_value = np.array([170,65,110])
maskBrown2 = cv2.inRange(hsv, lower_value, upper_value)
# Mask for red and brown
mask = maskRed+maskRed2+maskBrown+maskBrown2
pixDetected = cv2.countNonZero(mask)
# special case: average values not yet computed
if self.avgPix == -1:
self.avgPix = pixDetected
self.avgVola = minPix * sigma
# calc threshold (pixDetected must be higher for a valid object detection)
movingBand = self.avgVola * sigma
if movingBand < minPix:
movingBand = minPix
threshold = self.avgPix + movingBand
print("{0} Pix: {1:5d} Avg: {2:5.0f} Vola: {3:5.0f} Thresh: {4:5.0f} Bright: {5:3.0f} {6}{7}" \
.format(ts, pixDetected, self.avgPix, self.avgVola, threshold, brightness, \
"-" if self.night==True else " ", \
"T" if pixDetected >= threshold else ""))
# cv2.imwrite('result.jpg',mask)
# cv2.imwrite('result1.jpg',img)
# no object detection because it is night or amount of detected pixel is below threshold
if self.night or pixDetected < threshold:
# update average values
self.avgVola = abs(pixDetected-self.avgPix)*alpha + self.avgVola*(1-alpha)
self.avgPix = pixDetected*alpha + self.avgPix*(1-alpha)
return False
# valid object detection
# cv2.imwrite('Videos/'+ts+'-1.jpg',mask)
# cv2.imwrite('Videos/'+ts+'-2.jpg',img)
return True
...
Hier gibt es neben dem Konstruktor nur eine einzige Methode detect und die macht die ganze Farberkennung. Und nicht nur das, detect prüft auch die Bildhelligkeit und unterbindet die Videoaufzeichnung zur Nachtzeit. Was sehr sinnvoll ist, da wir keine Infrarotkamera haben und das Eichhörnchen auch eher tagaktiv ist.
detect bekommt das Bildimage übergeben und den Zeitstempel der Signaldatei. Zuerst kommt die Tag-Nacht-Erkennung dran. Dazu wird das ursprüngliche Farbbild in ein Graustufenbild verwandelt. Und hier kommt wieder OpenCV zum Einsatz – zur Formatumwandlung bringt OpenCV zahlreiche Konverter mit. Hier wird vom BGR-Farbraum (ja OpenCV verwendet per Standard BGR und nicht RGB) nach Grayscale gewandelt. Über alle Pixel des Graustufenbilds bilden wir dann einen Durchschnittswert, der ein Maß für die Bildhelligkeit sein soll. Dafür verwenden wir eine numpy-Funktion, die das in einer einzigen Programmzeile erledigt (np.average). Anhand der beiden global definierten Werte für Sonnenauf- und -untergang wird in den beiden folgenden if-Zeilen ermittelt, ob gerade Tag oder Nacht ist. Beim Tag- und Nachtschwellwert muss man ein wenig experimentieren, die sind auch stark vom jeweiligen Bild abhängig. Wichtig ist nur, dass der Sonnenaufgangswert etwas höher angesetzt wird als der für den Sonnenuntergang. Diese kleine Hysterese bewirkt, dass schlagartig und dauerhaft von Tag auf Nacht (und umgekehrt) umgeschaltet und nicht mehrfach hin- und hergezittert wird.

Sehr gute Erkennung
Nun geht es an die eigentliche Farbanalyse. Dazu wird das ursprüngliche Bild wieder in einen anderen Farbraum umgewandelt, nämlich von BGR nach HSV. Dann werden vier Farbbereiche definiert, jeweils zwei für rotbraune und zwei für dunkelbraune Eichhörnchen. Jeder der vier Farbbereiche hat für jeden Farbkanal – als da sind H (Hue), S (Saturation) und V (Value) – jeweils Minimum- und Maximumwerte. Das klingt jetzt sehr abstrakt, wir brauchen uns darüber im Moment aber noch nicht allzu viele Gedanken machen. Was es mit den Farbbereichen, den Minimal- und den Maximalwerten und dem HSV-Farbraum auf sich hat, wird noch in weiteren Artikeln detailliert erklärt. Die Bereiche der Minimal- bis Maximalwerte werden dann mit csv.inRange über das Bild gelegt und so die Bildbereiche quasi als Maske ermittelt, deren Farbwerte innerhalb dieser Ranges liegen. Danach werden die vier Masken nur noch auf eine einzige vereinigt. Anschaulicher wird das, wenn wir uns die Maske als Bild ansehen. Unten ist sie als Schwarzweißbild zu sehen, mit weißen Anteilen überall dort, wo im Ausgangsbild Farben aus den vier definierten Bereichen auftreten.
Man sieht im ersten Beispielbild eine sehr gute Erkennungssituation. Vom Bildhintergrund werden nahezu keine Pixel erkannt, vom rotbraunen Eichhörnchen jedoch sehr viele. Aber auch nicht alle, die weißen Bereiche im Fell fehlen in der Maske zum Beispiel. Das ist hier auch so gewollt. Leider ist die Erkennung nicht immer dermaßen gut, bei schwierigen Lichtverhältnissen zum Beispiel sind die Äste im Baum farblich kaum von einem dunkelbraunen Eichhörnchen zu unterscheiden.

Sehr eindeutige Erkennung, die gezählten Pixel übersteigen den Schwellwert um das 30-fache.
Was bildlich in der Schwarzweißmaske sehr gut zu erkennen ist, muss nun nur noch programmmäßig nachvollzogen werden. Dazu werden in der Maske einfach alle weißen (nonZero) Pixel gezählt. Die Höhe der Summe macht dann eine Aussage, wie viel Eichhörnchenfarbe im Bild enthalten ist.
Für erste Experimente könnte man nun einfach einen Schwellwert definieren. Liegt die Summe der weißen Pixel darüber, haben wir ein Eichhörnchen erkannt, liegt sie darunter, dann nicht. In der Realität ist es mit so einem starren Schwellwert aber eher schwierig. Rote und braune Eichhörnchen liefern unterschiedliche gute Farberkennung, jedes für sich auch unterschiedliche Werte, je nach dem, ob es quer zum Bild sitzt, oder direkt zur Kamera. Und ungünstigeLichtverhältnisse führen zu (wesentlich) mehr falsch positiven Pixelerkennungen im Bildhintergrund. Ich versuche deshalb im Programm eine adaptive Lösung zu finden, die sich den Lichtverhältnissen ein wenig anpassen kann.
Ein Mittel zum Zweck ist es, aus den Summen der Weißwerte (pixDetected) über viele Bilder hinweg einen gleitenden Durchschnitt zu bilden, anstelle eines festen Schwellwerts. Gleitende Durchschnitte kennt man zum Beispiel von der Börse in Form einer 200-Tagelinie, die an jedem Tag den Durchschnitt der letzten 200 Tage repräsentiert und so mit Verzögerung und geglättet dem entsprechenden Aktienkurs nachläuft. Ohne sich ständig sehr viele Vergangenheitswerte merken zu müssen, kann man einen gleitenden Durchschnitt auch vereinfacht dadurch berechnen, dass ein neu hinzu kommender Wert (Aktienkurs oder erkannte Pixelanzahl) einen definierten, aber vergleichsweise geringen Einfluss auf den Durchschnittswert bekommt. Im Programm sind das 10% oder ein Faktor von 0,1, der durch die Variable alpha repräsentiert wird. Der neu errechnete Durchschnittswert wird als self.avgPix gespeichert. Jede Sekunde geht also 10% des aktuellen Erkennungswerts (pixDetected), aber 90 des bisherigen Durchschnitts in den aktualisierten Durchschnitt ein. self.avgPix ist folglich ein gleitender Durchschnitt, der sich ständig an die aktuelle Pixelanzahl anpasst. Wohlgemerkt, wir sprechen vom Ruhezustand zu dem kein Eichhörnchen im Bild ist, also von eigentlich falsch positiv erkannten Pixel. Wenn wir deren Durchschnittswert nun kennen, dann können wir prüfen, ob ein aktueller Wert sich gravierend von Durchschnitt unterscheidet, was ein Hinweis auf ein Eichhörnchen wäre.
Das Programm geht aber noch einen Schritt weiter, denn die Unterschiede der aktuell ermittelten Pixelanzahl (pixDetected) von ihrem Durchschnitt (self.avgPix) können durchaus sehr unterschiedlich sein. Das macht es wieder schwierig, festzulegen, wann denn der Durchschnitt genügend überschritten ist. Wir können aber messen, wie weit ein aktueller Wert vom Durchschnitt entfernt ist und aus diesem Abstand ebenfalls einen gleitenden Durchschnitt bilden. Das wäre dann die durchschnittliche Volatilität (self.avgVola) und sie ist ein Maß für die Schwankungsbreite der erkannten Pixelanzahlen um ihren Durchschnitt.

Schlechte Lichtsituation, viele Äste werden als Eichhörnchenfarbe erkannt.
Damit haben wir jetzt einen adaptiven gleitenden Durchschnitt der erkannten Pixelanzahlen, basierend auf den Werten der vergangenen paar Sekunden und wir wissen wie stark die jeweiligen Pixelanzahlen um diesen Durschnitt schwanken. Damit können wir nun ein Band (movingBand) errechnen, das sich in einem bestimmten Abstand oberhalb des Durchschnitts (self.avgPix) bewegt und bei dessen Durchstoßen ein Eichhörnchen angenommen werden kann. Das Band ist nichts weiter als ein Vielfaches der durchschnittlichen Volatilität (self.avgVola). Den Verfielfachungsfaktor nennen wir sigma und legen ihn experimentell fest, 7 ist zum Beispiel ein guter Wert. Es muss also die 7-fache durchschnittliche Volatilität (Schwankungsbreite) überschritten werden, damit ein Eichhörnchen als erkannt gilt.
Eine Sache fehlt aber jetzt noch. Bei guter Beleuchtung kann die Anzahl der falsch positiv erkannten Pixel auf dem Bild ohne Eichhörnchen sehr gering sein (einstellig oder sogar null). Genau so, wie im ersten Beispielbild. Damit sinkt auch der entsprechende Durchschnittswert und bei geringer Schwankung auch die Volatilität. In so einem Moment, wenn die Schwellwerte sehr niedrig sind, reicht bereits eine kleine Bildänderung um eine falsche Auslösung zu erzeugen. Zum Beispiel wenn die Sonne plötzlich hinter einer Wolke hervor kommt und die Farbe der Äste verändert. Um das zu verhindern, führen wir eine absolute Untergrenze von Pixeln ein, die in jedem Fall erreicht werden muss. Das bedeutet, dass kleinere Farberkennungen von 100 oder 200 Pixel niemals zu einer Auslösung führen, weil ein Eichhörnchen immer wesentlich größer ist. Der Mindestwert heißt minPix, ist ebenfalls im Programm einleitend oben bei den Parametern mit 275 definiert und bildet die Mindestgröße für das movingBand.
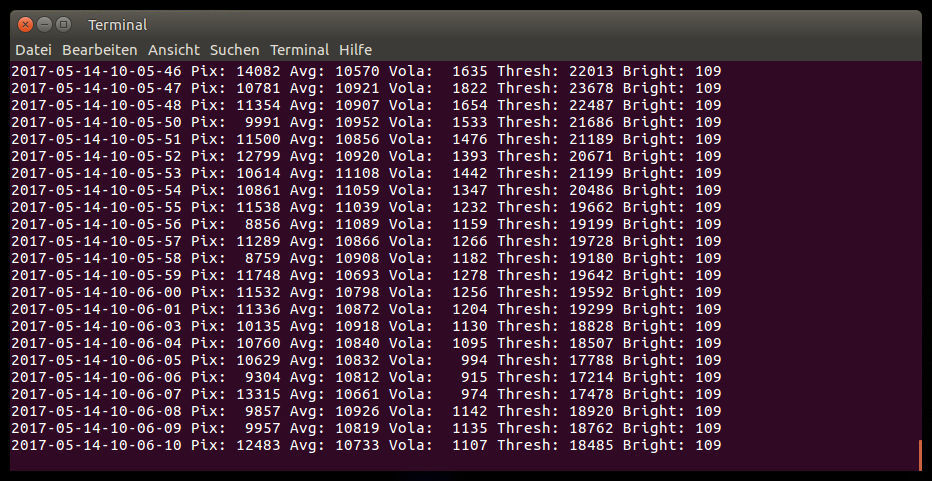
Schwierige Lichtsituation, viele falsch erkannte Pixel bereits im Ruhezustand, hohe Volatilität und sehr hoher Schwellwert.
Jetzt addieren wir noch das movingBand auf die durchschnittliche Pixelanzahl (self.avgPix) oben drauf und haben somit einen angepassten Schwellwert (threshold) für die Farberkennung. Wird die aktuelle Summe der erkannten Farbpixel – das ist alles, was auf der Maske weiß ist – größer als der threshold, dann haben wir ein Eichhörnchen erkannt und die Methode liefert True zurück. Im anderen Fall, also wenn zu wenig relevante Farbpixel erkannt werden, wird False zurückgegeben. Vorher werden aber noch die Durchschnittswerte self.avgPix und self.avgVola angepasst.
Der Rest dient nur der Veranschaulichung. In einem Printbefehl, der über drei Zeilen reicht, werden viele der eben berechneten Werte sekündlich ausgegeben, so dass man gut verfolgen kann, wie sie sich verändern (siehe Screenshots der beiden Terminalfenster). Hier kann man auch die Tag-Nacht-Umschaltung verfolgen und die Triggerereignisse an einem T am Ende der Zeile erkennen. Vier Programmzeilen mit cv2.imwrite-Befehlen sind auskommentiert. Die kann man experimentell aktivieren, dann werden im ersten Fall sekündlich Image und Maske als Bilddatei gespeichert. Oder im zweiten Fall ganz am Ende der Methode werden die Erkennungsbilder (Image und Maske) ins Verzeichnis zu den Videos kopiert. Hier kann man dann gut sehen, welche Erkennung zu welchen Videoaufzeichnungen führt. Für den Normalbetrieb sollte man aber die Erzeugung dieser Bilder wieder abdrehen.
Klasse triggerGenerator
...
class triggerGenerator:
def __init__(self):
self.triggered = False # Trigger currently active?
self.lastTrigger = datetime.datetime.now() # stores last time of trigger detction
def trigger(self, triggerSignal, ts):
if triggerSignal:
# set or prolongation of trigger signal (zero length file), when new trigger detected
if not self.triggered:
open(triggerPath+ts+triggerFileExt, 'w').close()
self.triggered = True
print('Triggerstart')
self.lastTrigger = datetime.datetime.now()
else:
# remove trigger signal (zero length file) if timed out
if not self.triggered:
return
now = datetime.datetime.now()
if (now - self.lastTrigger).total_seconds() > triggerTimeout:
triggerFiles = [f for f in os.listdir(triggerPath) if f.endswith(triggerFileExt)]
for f in triggerFiles:
os.remove(triggerPath+f)
self.triggered = False
print('Triggerstop')
...Die dritte Python-Klasse kümmert sich nun darum, dass ein erkanntes Eichhörnchen auch dazu führt, dass eine entsprechende Triggerdatei geschrieben wird, um die Videoaufzeichnung zu starten. Zur Erinnerung, Triggerdateien liegen im Verzeichnis trigger/ und haben als Dateinamen einen Datum-Zeit-Stempel (zum Beilspiel: 2016-08-26-08-05-00.trg), der den Triggerzeitpunkt repräsentiert. Einen Dateiinhalt haben sie nicht.
Die Methode trigger erhält im Aufruf das triggerSignal, also True oder False und den Timestamp ts, der aus der ursprünglichen Signaldatei stammt. Neben den Entscheidungen, ob eine Triggerdatei zu setzen, oder zu löschen ist, muss die Methode auch den aktuellen Status bis zum nächsten Aufruf vorhalten. Das passiert in den beiden Variablen self.triggered und self.lastTrigger, die im Konstruktor __init__ vorbesetzt werden. Und die Methode muss eine Aufgabe übernehmen, die früher der PIR-Bewegungssensor in Hardware erledigt hat, sie muss den Nachlauf des Videofilms steuern. Der Nachlauf ist die Zeit während der ein ausbleibendes Triggersignal wieder zurückkehren kann, bevor die Videoaufzeichnung abschaltet. Stellen wir uns vor, ein Eichhörnchen löst die Kamera aus und entfernt sich dann aus dem Bild. Nun darf die Kamera nicht sofort abschalten, sie weiß ja nicht, ob sich das Eichhörnchen nur ungünstig abgewendet hat und nicht vielleicht gleich wieder zurückkehrt. Erst wenn während der vorgegebenen Nachlaufzeit kein Eichhörnchen mehr erkannt wird, stoppt die Videoaufzeichnung. Das bedeutet natürlich auch, dass jedes Video am Ende für die Dauer der Nachlaufzeit den leeren Hintergrund filmt. Die Nachlaufzeit (triggerTimeout) ist hier mit 20 Sekunden definiert, das lässt sich am Programmanfang aber ändern. Die Methode selbst ist einfaches Python mit ein paar Fallausscheidungen ohne OpenCV, so dass ich mir die nähere Erklärung sparen kann.
Hauptprogramm
...
il = imageLoader()
ia = imageAnalyzer()
tg = triggerGenerator()
while True:
timeStamp, img = il.getImg()
tSignal = ia.detect(img, timeStamp)
tg.trigger(tSignal, timeStamp)
Der einfachste Programmteil ist das Mainprogram ganz am Ende. Der Reihe nach werden anhand der drei Klassen drei Objekte instanziiert und deren Methoden dann in einer Endlosschleife immer wieder aufgerufen. Dass das nicht beliebig schnell erfolgt, sondern geordnet im Sekundentakt, ist nicht das Verdienst des Hauptprogramms, dafür sorgt die Synchronisierung auf die Signaldateien im imageLoader.
Selber ausprobieren
Wer die Programmversionen mit dem Bewegungssensor bereits selbst getestet hat, der hat – wenn er die gleichen Namen für die Python-Programme verwendet wie ich – bereits record.py und motioninterrupt.py im Einsatz. Die neuen Programme für die Bildauswertung heißen jetzt record2.py und analyze.py. Die automatischen Programmstarts per rc.local müssen also angepasst werden. Dazu editieren wir die rc-local-Datei mit:
sudo nano /etc/rc.localund passen unsere Einträge wie folgt an (alles bitte vor dem abschließenden exit 0)
cd /home/pi
rm -f trigger/*
su pi -c 'python3 -u record2.py &> record.log &'
su pi -c 'python3 -u analyze.py &> analyze.log &'Zuvor empfehle ich, zumindest analyze.py eine Weile interaktiv auf der Konsole laufen zu lassen um die Programmausgaben direkt sehen zu können, ohne extra das Logfile zu öffnen.
Das Analyseprogramm ist wie abgebildet direkt einsetzbar, aber andere Kamerasituationen brauchen vielleicht spezielle Anpassungen. Das wichtigste ist die Anpassung der Farbbereiche, auf die hin ausgewertet werden soll. Dazu mehr in den folgenden Artikeln. Darüber hinaus muss vielleicht an ein paar Stellschrauben bei den Parametern am Programmanfang gedreht werden. Das ist speziell dann nötig, denn die Farbbereiche zwar richtig eingestellt sind, aber trotzdem zu viele falsch negative oder falsch positive Erkennungen passieren.
Nach der Videoauslösung per Bewegungssensor ist die Farbauswertung die zweite Triggermöglichkeit, die ich hier vorstelle. Beide sind nicht perfekt, das schicke ich gleich mal vorraus. Während der Bewegungssensor keine Eichhörnchen kennt und auf alles reagiert, was sich bewegt (und seien es die Äste im Wind), ist die Farbauswertung schon intelligenter und auch treffsicherer. Aber auch damit wird es Videoaufzeichnungen geben, auf denen kein Eichhörnchen zu sehen ist. Die Farberkennung hat da ihre Grenzen, wo im Hintergrund Farben vorhanden sind, die auch das Zielobjekt hat. In meiner Konstellation sind das die Äste der Kiefer, die farblich einem dunkelbraunen Eichhörnchen gleichen. Speziell bei Gegenlichtsituationen ist die Farbauswertung fehleranfällig, in Summe aber doch ein gutes Stück besser als der Bewegungssensor.
Weitere Artikel in dieser Kategorie:
- Raspberry Video Camera – Teil 1: Oachkatzl-Cam
- Raspberry Video Camera – Teil 2: Komponenten & Konzepte
- Raspberry Video Camera – Teil 3: Raspberry Pi Kamera Modul V2.1
- Raspberry Video Camera – Teil 4: Aufnahmeauslöser
- Raspberry Video Camera – Teil 5: Passiver Infrarot Bewegungssensor
- Raspberry Video Camera – Teil 6: Stromversorgung
- Raspberry Video Camera – Teil 7: Spannungsregler 5V
- Raspberry Video Camera – Teil 8: Montage Modell 850
- Raspberry Video Camera – Teil 9: Montage Kamera Modul
- Raspberry Video Camera – Teil 10: SW Installation Betriebssystem und Module
- Raspberry Video Camera – Teil 11: SW Python für die Kamera
- Raspberry Video Camera – Teil 12: SW Trigger per Bewegungssensor
- Raspberry Video Camera – Teil 13: SW Autostart und Überwachung
- Raspberry Video Camera – Teil 14: SW Installation Computer Vision (OpenCV 3.2)
- Raspberry Video Camera – Teil 15: SW Einzelbilder exportieren für die Farberkennung
- Raspberry Video Camera – Teil 17: Exkurs – Wie Computer Farben sehen
- Raspberry Video Camera – Teil 18: SW Farbkalibrierung
- Raspberry Video Camera – Teil 19: SW Kombinationstrigger
- Raspberry Video Camera – Teil 20: Exkurs – Farbdarstellung per 2D-Histogramm
- Raspberry Video Camera – Teil 21: Konzept einer selbstlernenden Farberkennung
- Raspberry Video Camera – Teil 22: SW selbstlernende Farberkennung in Python
- Raspberry Video Camera – Teil 23: Verbesserung durch ROI und Aufnahmezeitbegrenzung
- Raspberry Video Camera – Teil 24: Anpassung von Programmparametern
- Raspberry Video Camera – Teil 25: Zweite Kamera
- Raspberry Video Camera – Teil 26: Optimierungen gegen Frame Drops
- Raspberry Video Camera – Teil 27: Was kostet der Spaß?
- Raspberry Video Camera – Teil 28: Kamera Modell 200 mit Raspberry Pi Zero
- Raspberry Video Camera – Teil 29: Stromversorgung für Kamera Modell 200
- Raspberry Video Camera – Teil 30: Software für Kamera Modell 200
Hier hänge ich jetzt fest. Mein kleines Testprogramm:
import os
import cv2
import numpy as np
img = cv2.imread(‚record.jpg‘)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
liefert folgenden Fehler:
Traceback (most recent call last):
File „/home/pi/P3_Quellen/Test_cv2_01.py“, line 7, in
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.error: /home/pi/opencv-3.2.0/modules/imgproc/src/color.cpp:9748: error: (-215) scn == 3 || scn == 4 in function cvtColor
PS: Die Videos sind absolut toll.
Schwer zu sagen. Die Hochkommas um record.jpg kommen mir komisch vor. Wenn es das nicht ist, dann versuch es mal interaktiv und starte python3, mach die imports, lade das img und versuche die Konvertierung. Alles der Reihe nach von Hand. Ich tippe auf ein Problem mit der Jpg-Datei.
Die jpg-Datei war es.
Kleine Änderung mit großer Wirkung (die Hochkommas waren es nicht):
img = cv2.imread(„record.png“)
Meine Maske cv2.imwrite(‚result.jpg‘,mask) entspricht nun der im Beispiel angezeigten (Sehr gute Erkennung).
Vielen Dank für die schnelle Hilfe.